software-architecture · data-engineering
Key Takeaways from Designing Data-Intensive Applications
This guide explores the architectural principles and design patterns behind data-intensive applications, covering core concerns like reliability, scalability, and maintainability. It compares OLTP and OLAP systems, dives into data encoding formats (e.g., JSON, Protobuf, Avro), communication protocols (REST, RPC, message brokers), and deployment strategies like rolling upgrades. Ideal for developers and system architects building scalable, resilient backend systems
1. What is a Data-Intensive Application?
Modern applications increasingly rely on data, not just computational speed. These are known as data-intensive applications—systems where challenges stem from the volume, complexity, and speed of change of the data rather than from CPU constraints.
Such applications are built from a collection of standard components, each serving a specialized role:
- Databases: Persist data so it can be retrieved later.
- Caches: Store the results of expensive computations to improve performance.
- Search Indexes: Enable keyword or filter-based queries over datasets.
- Stream Processing: Handle real-time data through asynchronous message passing.
- Batch Processing: Periodically perform computations over large datasets.
Understanding how these pieces interact is key to building scalable, maintainable systems.
2. Core System Design Concerns
Successful systems share three primary attributes:
Reliability
A system is reliable if it continues to function correctly even when faced with failures—hardware issues, software bugs, or human mistakes. This means data should not be lost or corrupted, and services should remain available where possible.
Scalability
Scalability is the system's ability to handle growth—whether in user traffic, dataset size, or feature complexity. An ideal system allows you to increase capacity by adding resources, rather than having to re-architect the entire solution.
Maintainability
As systems evolve, they must remain easy to understand, debug, and extend. A maintainable system allows many developers to contribute without causing regressions, and adapts to new requirements with minimal disruption.
3. OLTP vs OLAP Systems
 Data-intensive systems often fall into two categories:
Data-intensive systems often fall into two categories:
| Property | Transaction Processing (OLTP) | Analytic Processing (OLAP) |
|---|---|---|
| Read Pattern | Quick lookup by key (few records) | Aggregations over large data sets |
| Write Pattern | Frequent small writes (e.g., user inputs) | Bulk loads from pipelines or data warehouses |
| Users | Customers interacting with applications | Analysts querying for insights |
| Data Focus | Current application state | Historical logs or event trails |
| Data Size | Gigabytes to terabytes | Terabytes to petabytes |
OLTP systems are designed for real-time responsiveness, while OLAP systems are optimized for high-throughput data analysis.
4. Data Encoding and Evolution
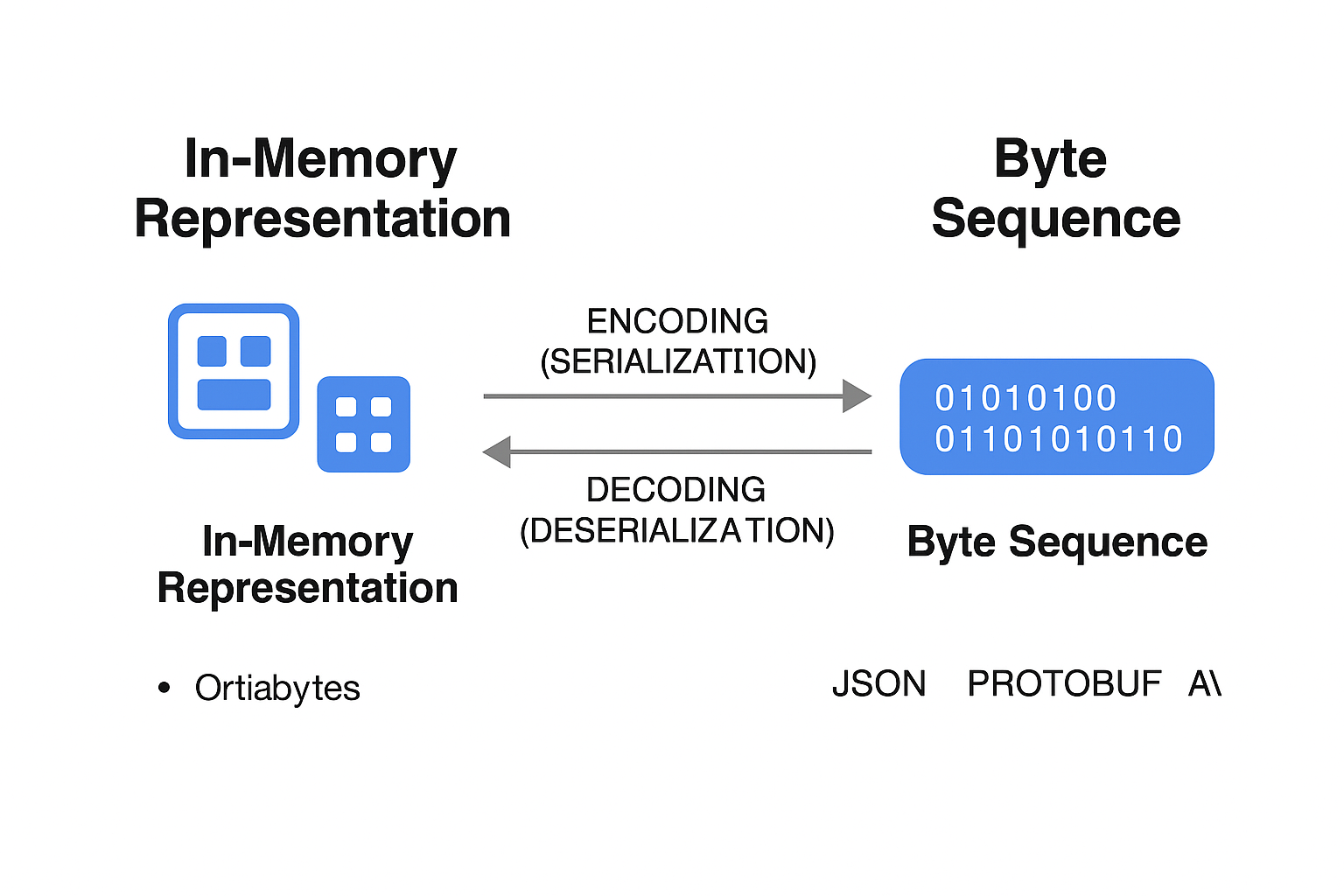
In-Memory vs Serialized Data
Applications store data in memory using structures like arrays, maps, or objects for fast access. However, this in-memory form isn't portable across systems.
When data is saved to disk or sent over the network, it must be encoded (or serialized) into a byte stream. This allows other systems to read or reconstruct it later using decoding (or deserialization).
Encoding Challenges
- Language Lock-In: Language-specific serialization (e.g., Java Serialization) makes it hard to integrate with services written in other languages.
- Security Vulnerabilities: Deserializing unknown input can expose systems to arbitrary code execution.
- Poor Versioning Support: Many formats don’t handle forward or backward compatibility, breaking systems when schemas evolve.
- Performance Overheads: Some encoders are bloated or slow, hindering throughput.
Format Comparisons
- Language-Specific (e.g., Java Serialization): Fast, but tightly coupled and insecure.
- Textual (e.g., JSON, XML): Human-readable and widely supported, but can be vague about types.
- Binary Schema-Driven (e.g., Protobuf, Avro): Efficient, compact, and explicitly versioned—ideal for internal service communication.
5. Communication Patterns
RPC (Remote Procedure Call)
RPC aims to abstract away the complexity of calling remote services by making them look like local function calls. However, this abstraction hides several issues:
- Unpredictability: Network calls are affected by latency, failures, and timeouts.
- Partial Failures: You might not know whether a request succeeded or failed if the response is lost.
- Duplicate Requests: Retrying on failure can lead to repeated operations without safeguards.
- Serialization Overhead: Complex objects must be encoded and decoded for each call.
- Cross-language Challenges: Data types may not translate cleanly between languages.
REST vs RPC
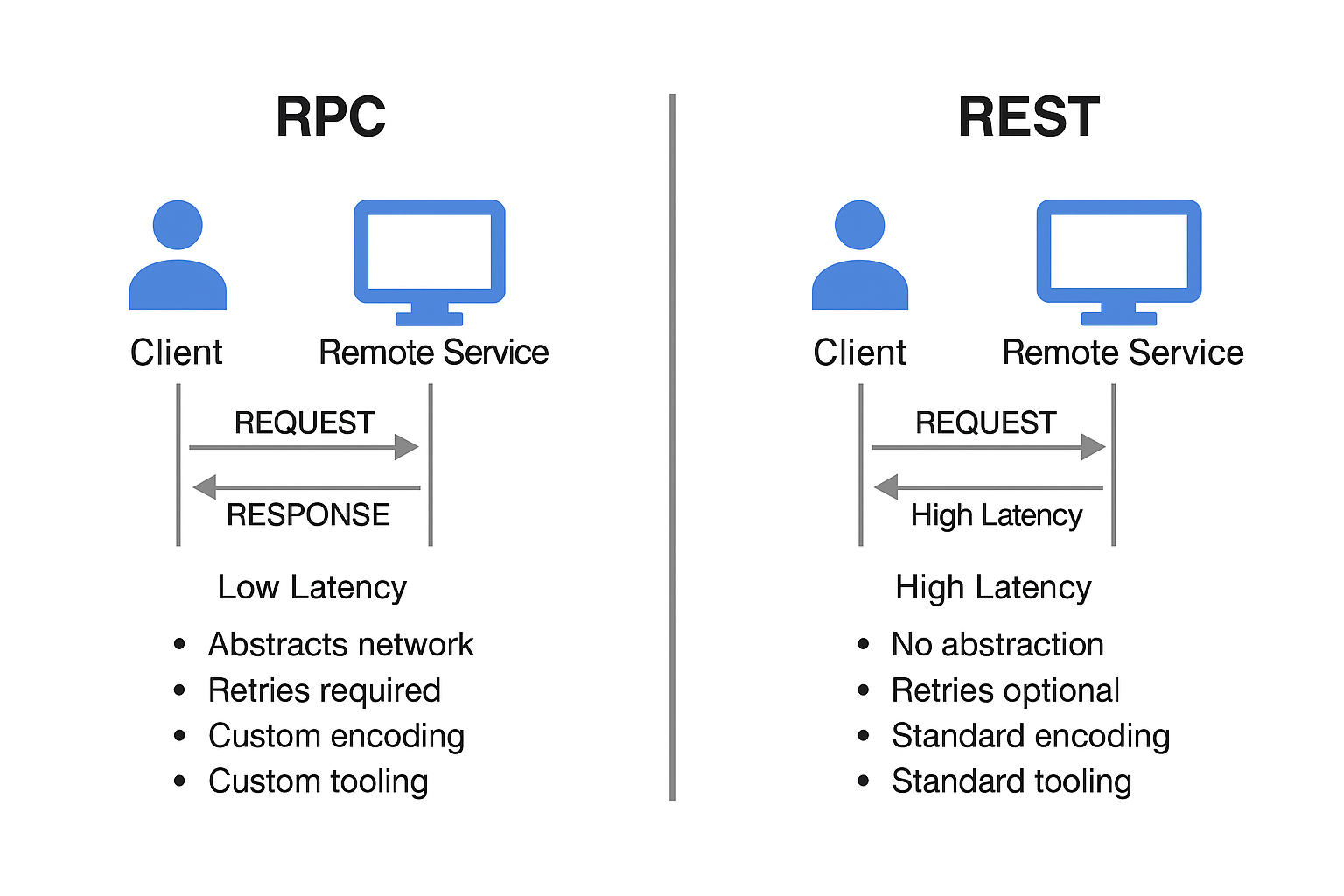
RESTful APIs offer a pragmatic alternative to RPC:
- Easy to test and debug with HTTP tools (like
curlor Postman). - Supported across all major platforms.
- Large ecosystem of tools (e.g., load balancers, proxies).
Custom RPC with binary formats can be faster, but REST is often preferred for public or heterogeneous systems.
Message-Passing with Brokers
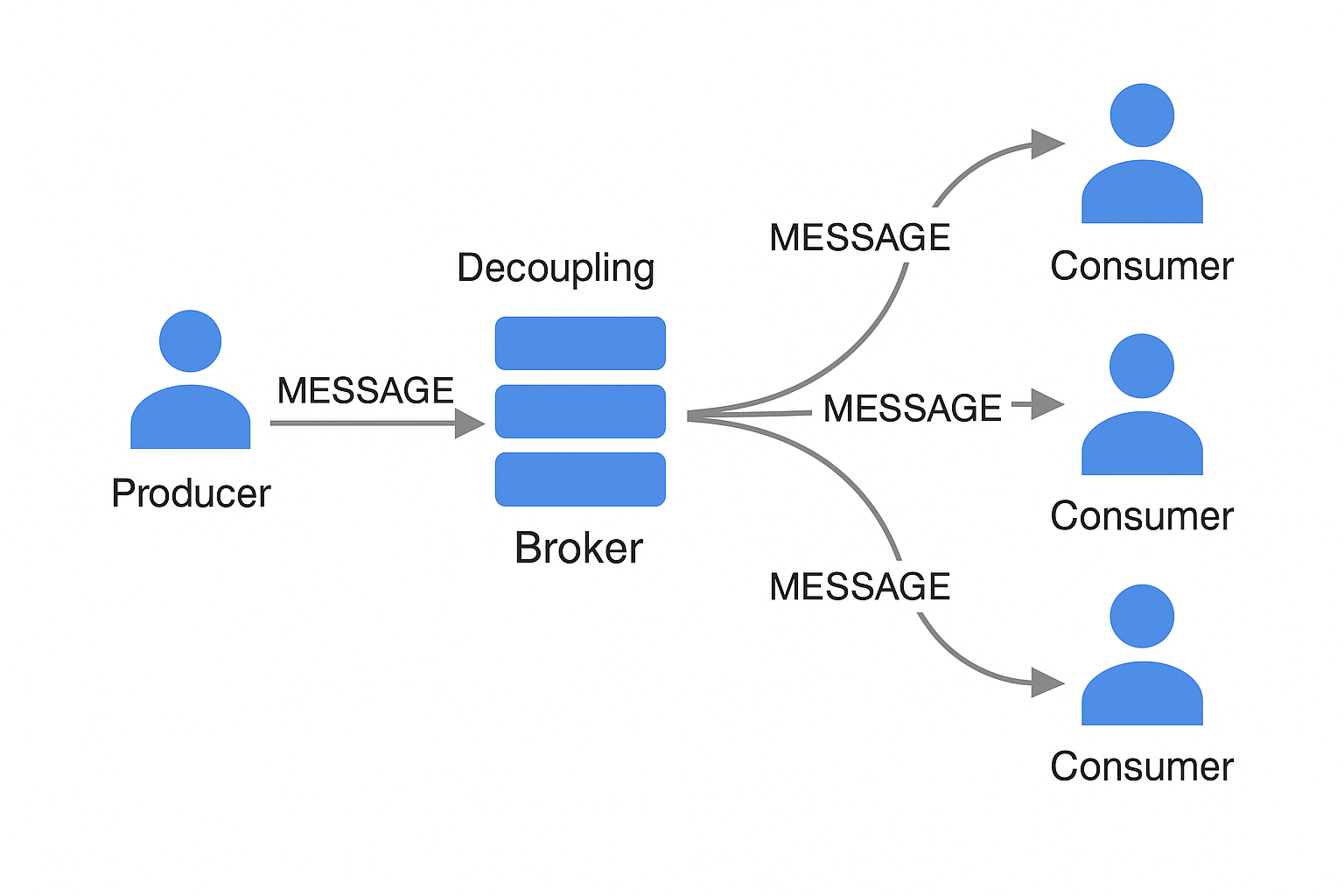
Messaging systems like Kafka or RabbitMQ offer an alternative model:
- Buffering: Acts as a queue when consumers are slow.
- Redelivery: Handles failures gracefully.
- Decoupling: Publishers don’t need to know consumers.
- Scalability: Enables multiple consumers per message.
- Asynchronous Flow: Send-and-forget communication.
Distributed Actor Frameworks
Actor models (like Akka) treat each component as a stateful actor communicating via messages. This model is naturally scalable and resilient and is suitable for building concurrent, distributed systems.
6. Deployment and Evolvability
Rolling Upgrades
Rolling upgrades involve gradually deploying new versions of a service to small subsets of servers:
- Reduce downtime and risk.
- Enable monitoring and rollback of faulty changes.
- Promote smaller, frequent deployments.
This strategy enhances evolvability, ensuring the system remains adaptable and continuously deployable.
7. Summary of Encoding Format Compatibility
| Format Type | Interoperability | Human-Readable | Versioning Support | Performance |
|---|---|---|---|---|
| Language-Specific | Low | No | Poor | Good |
| JSON/XML/CSV | High | Yes | Medium | Fair |
| Protobuf/Thrift/Avro | High | No | Strong | Excellent |
Conclusion
Designing robust data-intensive applications means making thoughtful decisions about storage, encoding, communication, and deployment.
Key takeaways:
- Use scalable architecture patterns to manage data growth.
- Choose encoding formats that support interoperability and evolution.
- Favor asynchronous communication for resilience.
- Implement rolling upgrades to deliver changes safely.
By embracing these principles, teams can build systems that are reliable under pressure, flexible for future needs, and efficient at scale.